Apache Zookeeper
Apache Zookeeper는 아파치 소프트웨어 재단의 소프트웨어 프로젝트이며, 대규모 분산 시스템에서의 분산된 서비스의 설정, 서비스의 동기화, 그리고 네이밍 레지스트리를 제공한다. Zookeeper는 Hadoop의 서브 프로젝트 였으나, 이제는 독립적인 프로젝트로서 자리잡았다.
1. Zookeeper Data Model
Zookeeper는 계층적인 네임 스페이스를 가지는데, 이는 분산 파일 시스템과 유사하다. 유일하게 다른점은 네임스페이스의 각 노드가 자식과 마찬가지로 연관될 수 있다는 점이다. 이는 마치 파일 시스템에서 파일이 디렉터리가 될 수 있도록 허용하는 것과 같다. 노드에 대한 경로는 항상 정석의, 절대적인, 슬래시로 구분되어지는 표현식을 쓰며, 상대경로는 없다. 경로 이름에 사용되는 유니코드 문자는 다음의 제약을 가진다.
- "zookeeper"는 예약어다.
- 널 문자(
\n0000)는 경로 이름에 포함될 수 없다. - "." 문자는 이름의 일부로 사용될 수 있지만, 단독으로는 사용할 수 없다. 상대경로가 지원되지 않기 때문
2. ZNodes
Zookeeper 트리의 각 노드는 znode라고 불린다. znode는 데이터 변경, ACL 변경에 대한 버전을 포함하는 stat 구조를 유지한다. 통계 구조에는 타임스탬프도 있다. 버전 번호와 타임스탬프를 통해 Zookeeper는 캐시를 확인하고 업데이트를 조정할 수 있다. znode의 데이터가 변경될 때마다 버전번호가 증가한다. 예를 들어, 클라이언트가 데이터를 검색할 때마다 데이터 버전도 받는다. 그리고 클라이언트가 업데이트 또는 삭제를 수행할 때 변경 중인 znode의 데이터 버전을 제공해야 한다. 제공하는 버전이 데이터의 실제 버전과 일치하지 않으면 업데이트가 실패한다. (이 동작은 override 가능하다.)
Note
분산 응용 프로그램 엔지니어링에서 노드 라는 단어 는 일반 호스트 시스템, 서버, 앙상블의 구성원, 클라이언트 프로세스 등을 나타낼 수 있다. ZooKeeper 설명서에서 znode 는 데이터 노드를 나타냅다. 서버 는 ZooKeeper 서비스를 구성하는 시스템을 나타냅다. 쿼럼 피어 는 앙상블을 구성하는 서버를 나타냅다. 클라이언트는 ZooKeeper 서비스를 사용하는 모든 호스트 또는 프로세스를 나타냅다.
Znode는 프로그래머가 액세스하는 주요 엔티티이다. 여기에 언급할 가치가 있는 몇 가지 특성이 있다.
Watches
클라이언트는 znode에서 Watch를 설정할 수 있다. 해당 znode에 대한 변경을 Watch를 트리거한 다음 Watch를 지우면된다. Watcher가 트리거되면 Zookeeper는 클라이언트에게 알림을 보낸다. ZooKeeper Watches
Data Access
네임스페이스의 각 znode에 저장된 데이터는 원자적으로 읽고 쓴다. 즉, 읽기는 znode와 관련된 모든 데이터 바이트를 가져오고, 쓰기는 모든 데이터를 대체한다. 각 노드에는 누가 무엇을 할 수 있는지를 제한하는 ACL(액세스 제어 목록)이 있다.
ZooKeeper는 일반 데이터베이스나 대형 개체 저장소로 설계되지 않았다. 대신 조정 데이터를 관리한다. 이 데이터는 구성, 상태 정보, 랑데뷰 등의 형태로 제공될 수 있다. 다양한 형태의 조정 데이터에서 공통적인 속성은 상대적으로 작다는 것이다. (킬로바이트 단위) ZooKeeper 클라이언트 및 서버 구현에는 znode에 1M 미만의 데이터가 있는지 확인하기 위한 온전성 검사가 있지만 데이터는 평균보다 훨씬 적어야 한다. 비교적 큰 데이터 크기에서 작업하면 일부 작업은 다른 작업보다 훨씬 더 많은 시간이 걸리고 네트워크를 통해 더 많은 데이터를 저장 매체로 이동하는 데 추가 시간이 필요하기 때문에, 일부 작업의 대기 시간에 영향을 미친다. 대용량 데이터 저장이 필요한 경우, 이러한 데이터를 처리하는 일반적인 패턴은 대용량 저장소 시스템에 저장하는 것이다.
3. ZooKeeper에서의 시간
ZooKeeper는 여러 가지 방법으로 시간을 추적한다:
- Zxid ZooKeeper 상태에 대한 모든 변경은 zxid (ZooKeeper 트랜잭션 ID) 형식의 스탬프를 받는다. 이는 ZooKeeper에 대한 모든 변경 사항의 전체 순서를 노출한다. 각 변경 사항은 고유한 zxid를 가지며 zxid1이 zxid2보다 작으면 zxid1이 zxid2보다 먼저 발생한다.
- Version numbers 노드를 변경할 때마다 해당 노드의 버전 번호 중 하나가 증가한다. 세 가지 버전 번호는 version(znode의 데이터에 대한 변경 수), cversion(znode의 자식에 대한 변경 수) 및 aversion(znode의 ACL에 대한 변경 수)이다.
- Ticks 다중 서버 ZooKeeper를 사용할 때 서버는 틱을 사용하여 상태 업로드, 세션 시간 초과, 피어 간 연결 시간 초과 등과 같은 이벤트의 타이밍을 정의한다. tick 시간은 최소 세션 시간 초과(틱 시간의 2배)를 통해 간접적으로만 노출된다. 클라이언트가 최소 세션 시간 초과보다 짧은 세션 시간 초과를 요청하면 서버는 클라이언트에게 세션 시간 초과가 실제로는 최소 세션 시간 초과임을 알린다.
- Real time ZooKeeper는 znode 생성 및 znode 수정 시 stat 구조에 타임스탬프를 넣는 것을 제외하고는 실시간 또는 Watch 시간을 전혀 사용하지 않는다.
4. ZooKeeper Stat Structure
ZooKeeper의 각 znode에 대한 Stat 구조는 다음 필드로 구성된다.
- czxid: znode를 생성한 변경 사항의 zxid
- mzxid: znode를 마지막으로 수정한 변경의 zxid
- pzxid: znode의 자식을 마지막으로 수정한 변경의 zxid
- ctime: znode가 생성된 시점부터의 시간(밀리초)
- mtime: znode가 마지막으로 수정된 Epoch로부터의 시간(밀리초)
- version: znode의 데이터에 대한 변경 수
- cversion: znode의 자식에 대한 변경 수
- aversion: znode의 ACL에 대한 변경 수
- ephemeralOwner: znode가 임시 노드인 경우 이 znode 소유자의 세션 ID이다. 임시 노드가 아니면 0이 됨
- dataLength: znode의 데이터 필드 길이
- numChildren: znode의 자식 수
5. ZooKeeper Sessions
ZooKeeper 클라이언트는 언어 바인딩을 사용하여 서비스에 대한 핸들을 만들어 ZooKeeper 서비스와 세션을 설정한다. 핸들이 생성되면 CONNECTING 상태에서 시작되고 클라이언트 라이브러리는 ZooKeeper 서비스를 구성하는 서버 중 하나에 연결을 시도하는 시점에서 CONNECTED 상태로 전환된다. 정상 작동 중에는 이 두 가지 상태 중 하나가 된다. 세션 만료 또는 인증 실패와 같은 복구할 수 없는 오류가 발생하거나 응용 프로그램이 핸들을 명시적으로 닫으면 핸들이 CLOSED 상태로 이동한다. 다음 그림은 ZooKeeper 클라이언트의 가능한 상태 전환을 보여준다.
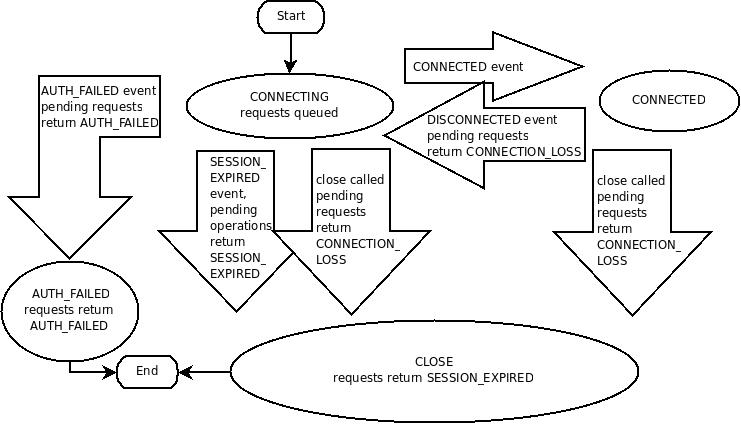
클라이언트 세션을 생성하려면 애플리케이션 코드가 각각 ZooKeeper 서버에 해당하는 쉼표로 구분된 호스트:포트 쌍 목록을 포함하는 연결 문자열을 제공해야 한다. (예: "127.0.0.1:4545" 또는 "127.0.0.1:3000,127.0.0.1 :3001,127.0.0.1:3002"). ZooKeeper 클라이언트 라이브러리는 임의의 서버를 선택하고 연결을 시도한다. 이 연결이 실패하거나 어떤 이유로 클라이언트가 서버에서 연결이 끊어지면 클라이언트는 연결이 (재)설정될 때까지 목록의 다음 서버를 자동으로 시도한다.
클라이언트가 ZooKeeper 서비스에 대한 핸들을 가져오면 ZooKeeper는 64비트 숫자로 표시되는 ZooKeeper 세션을 생성하여 클라이언트에 할당한다. 클라이언트가 다른 ZooKeeper 서버에 연결하면 연결 핸드셰이크의 일부로 세션 ID를 보낸다. 보안 조치로 서버는 ZooKeeper 서버가 확인할 수 있는 세션 ID에 대한 암호를 생성한다. 암호는 클라이언트가 세션을 설정할 때 세션 ID와 함께 클라이언트에 전송된다. 클라이언트는 새 서버와 세션을 다시 설정할 때마다 세션 ID와 함께 이 암호를 보낸다.
ZooKeeper 세션을 생성하기 위한 ZooKeeper 클라이언트 라이브러리 호출에 대한 매개변수 중 하나는 세션 시간 초과(밀리초)이다. 클라이언트는 요청된 시간 초과를 보내고 서버는 클라이언트에 제공할 수 있는 시간 초과로 응답한다. 현재 구현에서는 시간 제한이 tickTime의 최소 2배(서버 구성에서 설정됨)와 최대 tickTime의 20배가 되어야 한다. ZooKeeper 클라이언트 API는 협상된 시간 제한에 대한 액세스를 허용한다.
클라이언트(세션)가 ZK 서비스 클러스터에서 분할되면 세션 생성 중에 지정된 서버 목록을 검색하기 시작한다. 결국 클라이언트와 적어도 하나의 서버 간의 연결이 다시 설정되면 세션은 다시 "연결됨" 상태로 전환되거나(세션 시간 초과 값 내에서 다시 연결된 경우) "만료됨" 상태로 전환된다. (세션 시간 초과 후 다시 연결된 경우). 연결 해제를 위해 새 세션 개체(새 ZooKeeper.class 또는 c 바인딩의 Zookeeper 핸들)를 만드는 것은 권장되지 않는다. ZK 클라이언트 라이브러리가 재연결을 처리한다. 특히 "군집 효과" 등과 같은 것을 처리하기 위해 클라이언트 라이브러리에 휴리스틱을 내장하고 있다.
세션 만료는 클라이언트가 아닌 ZooKeeper 클러스터 자체에서 관리한다. ZK 클라이언트가 클러스터와 세션을 설정할 때 위에서 설명한 "시간 초과" 값을 제공한다. 이 값은 클러스터에서 클라이언트 세션이 만료되는 시기를 결정하는 데 사용된다. 만료는 클러스터가 지정된 세션 시간 초과 기간(즉, 하트비트 없음) 내에 클라이언트로부터 응답하지 않을 때 발생한다. 세션 만료 시 클러스터는 해당 세션이 소유한 모든 임시 노드를 삭제하고 연결된 모든 클라이언트(해당 znode를 보고 있는 모든 사용자)에게 즉시 변경 사항을 알린다. 이 시점에서 만료된 세션의 클라이언트는 여전히 클러스터에서 연결이 끊기며 클러스터에 대한 연결을 다시 설정할 수 있을 때까지/하지 않는 한 세션 만료를 알리지 않는다.
만료된 세션의 Watch자가 보는 만료된 세션의 상태 전환 예:
- ‘connected' : 세션이 설정되고 클라이언트가 클러스터와 통신 중(클라이언트/서버 통신이 제대로 작동 중)
- …. 클라이언트가 클러스터에서 분할되었다.
- ‘disconnected': 클라이언트와 클러스터의 연결이 끊어졌다.
- …. 시간 경과, ‘시간 초과' 기간 후 클러스터가 세션을 만료하고 클러스터에서 연결이 끊기므로 클라이언트에 아무 것도 표시되지 않는다.
- …. 시간이 경과하면 클라이언트가 클러스터와의 네트워크 수준 연결을 다시 얻는다.
- ‘expired': 결국 클라이언트가 클러스터에 다시 연결한 다음 만료 알림을 받는다.
ZooKeeper 세션 설정 호출에 대한 또 다른 매개변수는 기본 Watch자이다. 클라이언트에서 상태 변경이 발생하면 Watch자에게 알림이 전송된다. 예를 들어, 클라이언트가 서버에 대한 연결이 끊어지면 클라이언트에게 알림이 전송되거나 클라이언트의 세션이 만료되는 경우 등… 이 Watch자는 초기 상태가 연결이 끊어진 것으로 간주해야 한다. (상태 변경 이벤트가 Watch자에게 전송되기 전에 클라이언트 라이브러리) 새로운 연결의 경우 Watch자에게 보내는 첫 번째 이벤트는 일반적으로 세션 연결 이벤트이다.
세션은 클라이언트가 보낸 요청에 의해 활성 상태로 유지된다. 세션이 시간 초과되는 시간 동안 세션이 유휴 상태인 경우 클라이언트는 세션을 활성 상태로 유지하기 위해 PING 요청을 보낸다. 이 PING 요청을 통해 ZooKeeper 서버는 클라이언트가 여전히 활성 상태임을 알 수 있을 뿐만 아니라 클라이언트가 ZooKeeper 서버에 대한 연결이 여전히 활성 상태인지 확인할 수 있다. PING의 타이밍은 연결이 끊긴 것을 감지하고 새 서버에 다시 연결할 수 있는 합리적인 시간을 보장할 만큼 충분히 보수적이다.
서버에 대한 연결이 성공적으로 설정(연결)되면 기본적으로 동기 또는 비동기 작업이 수행되고 다음 중 하나가 유지된다.
- 애플리케이션이 더 이상 활성/유효하지 않은 세션에서 작업을 호출한다.
- ZooKeeper 클라이언트는 해당 서버에 대해 보류 중인 작업이 있는 경우, 즉 보류 중인 비동기 호출이 있는 경우 서버와의 연결을 끊는다.
서버 목록 업데이트 각각 ZooKeeper 서버에 해당하는 호스트:포트 쌍의 쉼표로 구분된 새 목록을 제공하여 클라이언트가 연결 문자열을 업데이트할 수 있도록 한다. 이 함수는 새 목록의 서버당 예상되는 균일한 수의 연결을 달성하기 위해 클라이언트가 현재 호스트에서 연결을 끊을 수 있는 확률적 로드 밸런싱 알고리즘을 호출한다. 클라이언트가 연결된 현재 호스트가 새 목록에 없는 경우 이 호출은 항상 연결을 끊는다. 그렇지 않으면 서버 수가 증가 또는 감소했는지 여부와 그 정도에 따라 결정이 내려진다.
예를 들어, 이전 연결 문자열에 3개의 호스트가 포함되어 있고 이제 목록에 이러한 3개의 호스트와 2개의 추가 호스트가 포함된 경우 3개의 호스트 각각에 연결된 클라이언트의 40%가 로드 균형을 맞추기 위해 새 호스트 중 하나로 이동한다. 알고리즘은 클라이언트가 0.4 확률로 연결된 현재 호스트에 대한 연결을 끊도록 하고 이 경우 클라이언트가 무작위로 선택된 2개의 새 호스트 중 하나에 연결하도록 한다.
또 다른 예 - 5개의 호스트가 있고 이제 호스트 중 2개를 제거하도록 목록을 업데이트한다고 가정하면 나머지 3개의 호스트에 연결된 클라이언트는 연결된 상태로 유지되는 반면 제거된 2개의 호스트에 연결된 모든 클라이언트는 다음 중 하나로 이동해야 한다. 무작위로 선택된 3명의 호스트. 연결이 끊어지면 클라이언트는 라운드 로빈이 아닌 확률적 알고리즘을 사용하여 연결할 새 서버를 선택하는 특수 모드로 이동한다.
첫 번째 예시에서 각 클라이언트는 확률 0.4로 연결을 끊기로 결정하지만 일단 결정이 내려지면 임의의 새 서버에 연결을 시도하고 새 서버에 연결할 수 없는 경우에만 이전 서버에 연결을 시도한다. 것. 서버를 찾거나 새 목록의 모든 서버를 시도하고 연결에 실패한 후 클라이언트는 connectString에서 임의의 서버를 선택하고 연결을 시도하는 정상 작동 모드로 다시 이동한다. 실패하면 라운드 로빈에서 다른 임의 서버를 계속 시도한다. (처음에 서버를 선택하는 데 사용된 알고리즘 위 참조)
6. ZooKeeper Watches
ZooKeeper의 모든 읽기 작업은 세 가지를 통해 이루어진다. getData() , getChildren() exists() 이는 Watch를 사이드 이팩트로 설정하는 옵션이 있다. 다음은 Watch에 대한 ZooKeeper의 정의이다. Watch 이벤트는 Watch를 설정한 클라이언트로 전송되는 일회성 트리거로, Watch가 설정된 데이터가 변경될 때 발생한다. Watch 정의에서 고려해야 할 세 가지 핵심 사항이 있다.
- 일회성 트리거 데이터가 변경되면 하나의 Watch 이벤트가 클라이언트로 전송된다. 예를 들어, 클라이언트가 getData("/znode1", true)를 수행하고 나중에 /znode1에 대한 데이터가 변경되거나 삭제되면 클라이언트는 /znode1에 대한 Watch 이벤트를 받게 된다. /znode1이 다시 변경되면 클라이언트가 새로운 Watch를 설정하는 다른 읽기를 수행하지 않는 한 Watch 이벤트가 전송되지 않는다.
- 클라이언트로 전송 이것은 이벤트가 클라이언트로 가는 중이지만 변경 작업에 대한 성공적인 반환 코드가 변경을 시작한 클라이언트에 도달하기 전에 클라이언트에 도달하지 못할 수 있음을 의미한다. Watch자는 Watch자에게 비동기식으로 전송된다. ZooKeeper는 순서 보장을 제공한다. 클라이언트는 Watch 이벤트를 처음 볼 때까지 Watch를 설정한 변경 사항을 절대 볼 수 없다. 네트워크 지연 또는 기타 요인으로 인해 다른 클라이언트가 다른 시간에 업데이트에서 Watch 및 반환 코드를 볼 수 있다. 요점은 다른 클라이언트가 보는 모든 것이 일관된 순서를 갖는다는 것이다.
- Watch가 설정된 데이터 이것은 노드가 변경될 수 있는 다양한 방법을 나타낸다. ZooKeeper는 데이터 Watch와 하위 Watch의 두 가지 Watch 목록을 유지 관리하는 것으로 생각하는 데 도움이 된다. getData() 및 extists()은 데이터 Watch를 설정한다. getChildren()은 자식 Watch를 설정한다. 또는 반환된 데이터의 종류에 따라 Watch를 설정하는 것으로 생각하면 도움이 될 수 있다. getData() 및 exist()는 노드의 데이터에 대한 정보를 반환하는 반면 getChildren()은 자식 목록을 반환한다. 따라서 setData()는 설정 중인 znode에 대한 데이터 Watch를 트리거한다. (설정이 성공했다고 가정). create()가 성공하면 생성되는 znode에 대한 데이터 Watch와 상위 znode에 대한 자식 Watch가 트리거된다. 성공적인 delete()는 삭제되는 znode에 대한 데이터 Watch와 자식 Watch(더 이상 자식이 있을 수 없기 때문에)와 부모 znode에 대한 자식 Watch를 모두 트리거한다.
Watch는 클라이언트가 연결된 ZooKeeper 서버에서 로컬로 유지 관리된다. 이를 통해 Watch를 경량으로 설정, 유지 관리 및 발송할 수 있다. 클라이언트가 새 서버에 연결하면 모든 세션 이벤트에 대해 Watch가 트리거된다. 서버와의 연결이 끊어진 상태에서는 Watch가 수신되지 않는다. 클라이언트가 다시 연결되면 이전에 등록된 모든 Watch가 다시 등록되고 필요한 경우 트리거된다. 일반적으로 이 모든 것이 투명하게 발생한다. Watch를 놓칠 수 있는 한 가지 경우가 있다. 연결이 끊긴 상태에서 znode가 생성되고 삭제되면 아직 생성되지 않은 znode의 존재에 대한 Watch가 누락된다.
Semantics of Watches
ZooKeeper의 상태를 읽는 세 가지 호출(exists, getData 및 getChildren)로 Watch를 설정할 수 있다. 다음 목록은 Watch가 트리거할 수 있는 이벤트와 이를 활성화하는 함수 호출에 대해 자세히 설명한다.
- 생성된 이벤트: exists 호출로 활성화
- 삭제된 이벤트: exists, getData 및 getChildren 호출로 활성화
- 변경된 이벤트: exists 및 getData에 대한 호출로 활성화
- 자식 이벤트: getChildren 호출로 활성화
Watch 제거
removeWatches를 호출하여 znode에 등록된 Watch를 제거할 수 있다. 또한 ZooKeeper 클라이언트는 로컬 플래그를 true로 설정하여 서버 연결이 없더라도 로컬에서 Watch를 제거할 수 있다. 다음 목록은 Watch가 성공적으로 제거된 후 트리거될 이벤트를 자세히 설명한다.
- 자식 제거 이벤트: getChildren 호출과 함께 추가된 Watcher
- 데이터 제거 이벤트: exists 또는 getData를 호출하여 추가된 Watcher
- Persistent Remove 이벤트: Persistent Watch를 추가하라는 호출과 함께 추가된 Watcher
ZooKeeper가 Watch에 대해 보증하는 것
Watch와 관련하여 ZooKeeper는 다음과 같은 보증을 유지한다.
- Watch는 다른 이벤트, 다른 Watch 및 비동기 응답과 관련하여 정렬된다. ZooKeeper 클라이언트 라이브러리는 모든 것이 순서대로 전달되도록 한다.
- 클라이언트는 해당 znode에 해당하는 새 데이터를 보기 전에 보고 있는 znode에 대한 Watch 이벤트를 보게 된다.
- ZooKeeper의 Watch 이벤트 순서는 ZooKeeper 서비스에 표시되는 업데이트 순서와 일치한다.
Watch에 대해 기억해야 할 사항
- 표준 Watch는 일회성 트리거이다. Watch 이벤트를 받고 향후 변경 사항에 대한 알림을 받으려면 다른 Watch를 설정해야 한다.
- 표준 Watch는 일회성 트리거이고 이벤트를 가져오고 Watch를 가져오기 위해 새 요청을 보내는 사이에 대기 시간이 있기 때문에 ZooKeeper에서 노드에 발생하는 모든 변경 사항을 안정적으로 볼 수는 없다. 이벤트를 가져오고 다시 Watch를 설정하는 사이에 znode가 여러 번 변경되는 경우를 처리할 준비를 하십시오. (신경 쓰지 않을 수도 있지만 적어도 일어날 수 있다는 것을 깨닫는다.)
- Watch 개체 또는 함수/컨텍스트 쌍은 지정된 알림에 대해 한 번만 트리거된다. 예를 들어, 동일한 Watch 객체가 존재하고 동일한 파일에 대한 getData 호출이 있고 그 파일이 삭제되는 경우 Watch 객체는 파일에 대한 삭제 알림과 함께 한 번만 호출된다.
- 서버에서 연결을 끊으면(예: 서버가 실패할 때) 연결이 다시 설정될 때까지 Watch를 받지 않는다. 이러한 이유로 세션 이벤트는 모든 미해결 Watch 핸들러로 전송된다. 세션 이벤트를 사용하여 안전 모드로 전환한다. 연결이 끊긴 동안에는 이벤트를 수신하지 않으므로 프로세스는 해당 모드에서 보수적으로 작동해야 한다.
7. ACL을 사용한 ZooKeeper 액세스 제어
ZooKeeper는 ACL을 사용하여 znode(ZooKeeper 데이터 트리의 데이터 노드)에 대한 액세스를 제어한다. ACL 구현은 UNIX 파일 액세스 권한과 매우 유사한다. 권한 비트를 사용하여 노드 및 비트가 적용되는 범위에 대한 다양한 작업을 허용/비허용한다. 표준 UNIX 권한과 달리 ZooKeeper 노드는 사용자(파일 소유자), 그룹 및 세계(기타)에 대한 세 가지 표준 범위로 제한되지 않는다. ZooKeeper에는 znode의 소유자라는 개념이 없다. 대신 ACL은 해당 ID와 연결된 권한 및 ID 세트를 지정한다.
또한 ACL은 특정 znode에만 적용된다. 특히 어린이에게는 적용되지 않는다. 예를 들어 /app 이 ip:172.16.16.1에서만 읽을 수 있고 /app/status 가 전 세계에서 읽을 수 있는 경우 누구나 /app/status 를 읽을 수 있다 . ACL은 재귀적이지 않는다.
ZooKeeper는 플러그형 인증 체계를 지원한다. ID는 schema:expression 형식을 사용하여 지정된다. 여기서 scheme 은 ID가 해당하는 인증 체계이다. 유효한 표현식 세트는 체계에 의해 정의된다. 예를 들어, ip:172.16.16.1 은 ip 체계 를 사용 하는 주소가 172.16.16.1 인 호스트의 id 이고, digest:bob:password 는 다이제스트 체계 를 사용하는 bob 이름을 가진 사용자의 id이다 .
클라이언트가 ZooKeeper에 연결하고 자신을 인증하면 ZooKeeper는 클라이언트에 해당하는 모든 ID를 클라이언트 연결과 연결한다. 이 ID는 클라이언트가 노드에 액세스하려고 할 때 znode의 ACL에 대해 확인된다. ACL은 (scheme:expression, perms) 쌍으로 구성 된다. 표현식 의 형식은 체계에 따라 다릅다. 예를 들어, 쌍 (ip:19.22.0.0/16, READ) 은 19.22로 시작하는 IP 주소를 가진 모든 클라이언트에 읽기 권한을 부여한다.
8. 일관성 보장
ZooKeeper는 고성능의 확장 가능한 서비스이다. 읽기와 쓰기 작업은 모두 빠르도록 설계되었지만 읽기는 쓰기보다 빠릅다. 그 이유는 읽기의 경우 ZooKeeper가 이전 데이터를 제공할 수 있기 때문이며 이는 ZooKeeper의 일관성 보장 때문이다.
- 순차 일관성 : 클라이언트의 업데이트가 전송된 순서대로 적용된다.
- 원자성 : 업데이트가 성공하거나 실패한다. 부분적인 결과가 없다.
- 단일 시스템 이미지 : 클라이언트는 연결하는 서버에 관계없이 동일한 서비스 보기를 볼 수 있다. 즉, 클라이언트가 동일한 세션의 다른 서버로 장애 조치를 취하더라도 클라이언트는 시스템의 이전 보기를 볼 수 없다.
- 안정성 : 업데이트가 적용된 후에는 클라이언트가 업데이트를 덮어쓸 때까지 계속 유지된다. 이 보증에는 두 가지 결과가 있다.
- 클라이언트가 성공적인 반환 코드를 받으면 업데이트가 적용된 것이다. 일부 오류(통신 오류, 시간 초과 등)에서 클라이언트는 업데이트가 적용되었는지 여부를 알 수 없다. 우리는 실패를 최소화하기 위한 조치를 취하지만 성공적인 반환 코드에서만 보증이 제공된다. (이를 Paxos 에서는 단조성 조건 이라고 한다.)
- 읽기 요청 또는 성공적인 업데이트를 통해 클라이언트가 보는 모든 업데이트는 서버 오류에서 복구할 때 롤백되지 않는다.
- 적시성 : 시스템의 클라이언트 보기는 특정 시간 범위(수십 초 정도) 내에서 최신 상태가 되도록 보장된다. 시스템 변경 사항은 이 경계 내에서 클라이언트에 표시되거나 클라이언트가 서비스 중단을 감지한다.
이러한 일관성 보장을 사용하면 ZooKeeper 클라이언트에서만 리더 선택, 장벽, 대기열 및 읽기/쓰기 취소 가능한 잠금과 같은 더 높은 수준의 기능을 쉽게 구축할 수 있다(ZooKeeper에 추가할 필요 없음).
Note
때때로 개발자는 실수로 ZooKeeper가 실제로 하지 않는 다른 보증을 가정 한다. * 동시적으로 일관된 클라이언트 간 보기* : ZooKeeper는 모든 인스턴스에서 두 개의 서로 다른 클라이언트가 ZooKeeper 데이터에 대해 동일한 보기를 가질 것이라고 보장하지 않는다. 네트워크 지연과 같은 요인으로 인해 한 클라이언트는 다른 클라이언트가 변경 사항을 알리기 전에 업데이트를 수행할 수 있다. 두 클라이언트 A와 B의 시나리오를 고려하십시오. 클라이언트 A가 znode /a의 값을 0에서 1로 설정하고 클라이언트 B에게 /a를 읽도록 지시하면 클라이언트 B는 어떤 서버에 따라 이전 값 0을 읽을 수 있다. 에 연결되어 있다. 클라이언트 A와 클라이언트 B가 동일한 값을 읽는 것이 중요한 경우 클라이언트 B는 sync()읽기를 수행하기 전에 ZooKeeper API 메서드에서 메서드를 가져옵다. 따라서 ZooKeeper 자체는 변경 사항이 모든 서버에서 동기적으로 발생하는 것을 보장하지 않지만 ZooKeeper 기본 요소를 사용하여 유용한 클라이언트 동기화를 제공하는 더 높은 수준의 기능을 구성할 수 있다.
9. 바인딩
ZooKeeper 클라이언트 라이브러리는 Java 및 C의 두 가지 언어로 제공된다. 다음 섹션에서는 이에 대해 설명한다.
자바 바인딩
ZooKeeper Java 바인딩을 구성하는 두 가지 패키지가 있다. org.apache.zookeeper 및 org.apache.zookeeper.data . ZooKeeper를 구성하는 나머지 패키지는 내부적으로 사용되거나 서버 구현의 일부이다. org.apache.zookeeper.data 패키지 는 단순히 컨테이너로 사용되는 생성된 클래스로 구성된다.
ZooKeeper Java 클라이언트에서 사용하는 기본 클래스는 ZooKeeper 클래스이다. 두 생성자는 선택적 세션 ID와 암호만 다릅다. ZooKeeper는 프로세스 인스턴스 간의 세션 복구를 지원한다. Java 프로그램은 세션 ID와 암호를 안정적인 저장소에 저장하고 프로그램의 이전 인스턴스에서 사용한 세션을 다시 시작하고 복구할 수 있다.
ZooKeeper 개체가 생성되면 IO 스레드와 이벤트 스레드라는 두 개의 스레드도 생성된다. 모든 IO는 IO 스레드에서 발생한다(Java NIO 사용). 모든 이벤트 콜백은 이벤트 스레드에서 발생한다. ZooKeeper 서버에 다시 연결하고 하트비트를 유지하는 것과 같은 세션 유지 관리는 IO 스레드에서 수행된다. 동기 메서드에 대한 응답도 IO 스레드에서 처리된다. 비동기 메서드 및 Watch 이벤트에 대한 모든 응답은 이벤트 스레드에서 처리된다. 이 디자인에서 알 수 있는 몇 가지 사항이 있다.
- 비동기 호출 및 Watch자 콜백에 대한 모든 완료는 한 번에 하나씩 순서대로 수행된다. 호출자는 원하는 모든 처리를 수행할 수 있지만 해당 시간 동안 다른 콜백은 처리되지 않는다.
- 콜백은 IO 스레드의 처리 또는 동기 호출의 처리를 차단하지 않는다.
- 동기 호출은 올바른 순서로 반환되지 않을 수 있다. 예를 들어 클라이언트가 다음 처리를 수행한다고 가정한다. Watch 가 true 로 설정된 노드 /a 의 비동기 읽기를 실행한 다음 읽기 완료 콜백에서 /a 의 동기 읽기를 수행 한다 . (좋은 습관은 아니지만 불법도 아니고 간단한 예이다.) 비동기 읽기와 동기 읽기 사이 에 /a 가 변경되면 클라이언트 라이브러리는 /a 라는 Watch 이벤트를 수신한다. 동기 읽기에 대한 응답 전에 변경되었지만 이벤트 큐를 차단하는 완료 콜백으로 인해 동기 읽기는 /a 의 새 값으로 반환된다. Watch 이벤트가 처리되기 전에
마지막으로 종료와 관련된 규칙은 간단한다. ZooKeeper 개체가 닫히거나 치명적인 이벤트(SESSION_EXPIRED 및 AUTH_FAILED)를 받으면 ZooKeeper 개체가 무효화된다. 닫히면 두 스레드가 종료되고 Zookeeper 핸들에 대한 추가 액세스는 정의되지 않은 동작이므로 피해야 한다.
10. 일반적인 문제 및 문제 해결
이제 ZooKeeper를 알게 되었다. 빠르고 간단하며 응용 프로그램이 작동하지만 잠시만 기다려 주십시오. 뭔가 잘못되었다. 다음은 ZooKeeper 사용자가 빠지는 몇 가지 함정이다.
- Watch를 사용하는 경우 연결된 Watch 이벤트를 찾아야 한다. ZooKeeper 클라이언트가 서버에서 연결을 끊으면 다시 연결될 때까지 변경 알림을 받지 못한다. znode가 생성되기를 지켜보고 있다면 연결이 끊긴 상태에서 znode가 생성되고 삭제되면 이벤트를 놓칠 것이다.
- ZooKeeper 서버 오류를 테스트해야 한다. ZooKeeper 서비스는 대부분의 서버가 활성 상태인 한 장애를 극복할 수 있다. 물어볼 질문은 다음과 같다. 귀하의 애플리케이션이 이를 처리할 수 있습니까? 현실 세계에서는 ZooKeeper에 대한 클라이언트의 연결이 끊어질 수 있다. (ZooKeeper 서버 오류 및 네트워크 파티션은 연결 손실의 일반적인 원인이다.) ZooKeeper 클라이언트 라이브러리는 연결 복구를 처리하고 무슨 일이 일어났는지 알려주지만 상태와 실패한 모든 미해결 요청을 복구해야 한다. 프로덕션이 아닌 테스트 랩에서 올바르게 수행했는지 확인하십시오. 여러 대의 서버로 구성된 ZooKeeper 서비스로 테스트하고 재부팅하십시오.
- 클라이언트에서 사용하는 ZooKeeper 서버 목록은 각 ZooKeeper 서버에 있는 ZooKeeper 서버 목록과 일치해야 한다. 클라이언트 목록이 ZooKeeper 서버의 실제 목록의 하위 집합인 경우 최적은 아니지만 작동할 수 있지만 클라이언트가 ZooKeeper 클러스터에 없는 ZooKeeper 서버를 나열하는 경우에는 작동하지 않는다.
- 해당 트랜잭션 로그를 저장하는 위치에 주의하십시오. ZooKeeper에서 가장 성능이 중요한 부분은 트랜잭션 로그이다. ZooKeeper는 응답을 반환하기 전에 트랜잭션을 미디어와 동기화해야 한다. 전용 트랜잭션 로그 장치는 일관되고 우수한 성능의 핵심이다. 사용 중인 장치에 로그를 기록하면 성능이 저하된다. 저장 장치가 하나만 있는 경우 NFS에 추적 파일을 넣고 snapshotCount를 늘리십시오. 문제를 제거하지는 않지만 완화할 수 있다.
- Java 최대 힙 크기를 올바르게 설정하십시오. 교환을 피하는 것이 매우 중요한다 . 불필요하게 디스크로 이동하면 거의 확실히 성능이 허용할 수 없을 정도로 저하된다. ZooKeeper에서는 모든 것이 순서가 지정되어 있으므로 하나의 요청이 디스크에 도달하면 대기 중인 다른 모든 요청이 디스크에 도달한다는 것을 기억하십시오. 스와핑을 방지하려면 힙 크기를 보유한 실제 메모리 양에서 OS 및 캐시에 필요한 양을 뺀 값으로 설정하십시오. 구성에 대한 최적의 힙 크기를 결정하는 가장 좋은 방법은 부하 테스트를 실행하는 것 이다. 어떤 이유로 할 수 없는 경우 추정치를 보수적으로 유지하고 컴퓨터를 교체할 수 있는 한계보다 훨씬 낮은 숫자를 선택하십시오. 예를 들어, 4G 머신에서 3G 힙은 처음부터 보수적인 추정치이다.
References
- https://hub.docker.com/_/zookeeper
- API Reference : The complete reference to the ZooKeeper API
- ZooKeeper Talk at the Hadoop Summit 2008 : A video introduction to ZooKeeper, by Benjamin Reed of Yahoo! Research
- Barrier and Queue Tutorial : The excellent Java tutorial by Flavio Junqueira, implementing simple barriers and producer-consumer queues using ZooKeeper.
- ZooKeeper - A Reliable, Scalable Distributed Coordination System : An article by Todd Hoff (07/15/2008)
- ZooKeeper Recipes : Pseudo-level discussion of the implementation of various synchronization solutions with ZooKeeper: Event Handles, Queues, Locks, and Two-phase Commits.